Поиск по сайту - статичный контент (Perl)
Поиск по сайту, не самый сложный элемент, но довольно муторный. Так не хочется его делать, а надо. Я не буду рассматривать возможности внедрения в сайт поисковых форм Яндекса или Google, про это можно почитать у них самих. Будем делать собственный поиск по сайту.
Итак, что у нас дано:
-
сайт состоящий из статичных страниц;
-
файлы страниц расположены в разных папках различного уровня (у меня CMS собирает ЧПУ);
-
база данных MySQL (не использовать базу данных в поисковой машине - странное занятие, тем более что сейчас базы данных уже не роскошь);
Для того что бы у нас осуществлялся поиск нужно будет собрать "поисковые индексы". Я использую для этого два способа (способов, на самом деле, гораздо больше): простой и немного сложнее. В первом я использую встроенные функции MySQL базы данных, во втором - собственный велосипед.
Определим алгоритм работы скрипта индексирования поисковой машины (основные подпрограммы):
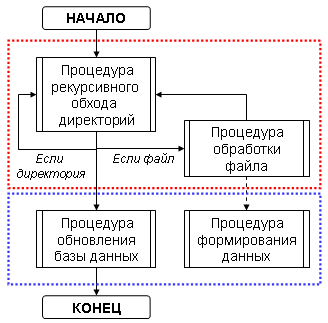
Красным пунктиром выделены стандартные процедуры для обоих способов, процедуры выделенные синим радикально отличаются.
- Процедура рекурсивного обхода директорий - процедура, последовательно проходящая по файлам и папкам нашего сайта и выбирающая нужные файлы;
- Процедура обработки файла - процедура, обрабатывающая контент файла;
- Процедура формирования данных - обработанный контент собирается в блок данных для переноса в базу данных;
- Процедура обновления базы данных - сформированный блок данных заносится в базу данных;
Алгоритм работы скрипта вывода результатов поиска:
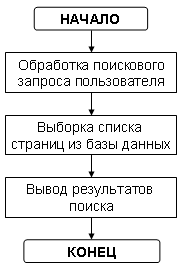
Данный скрипт нужно максимально упростить, так как индексацию мы запускаем максимум раз в сутки, то поисковый скрипт запускается на несколько порядков больше раз и тратить ресурсы во время поиска - нецелесообразно. Для этого требуется максимально оптимизировать информацию в базе данных, что бы она возвращала нам максимально подготовленную информацию для вывода, чтобы не производить лишних манипуляций.
Какая информация нужна нам для вывода результатов запроса:
-
URL страницы - ссылка на найденную страницу;
-
название страницы - эту информацию мы будем брать из тега <title> страницы;
-
краткое описание страницы - эту информацию мы будем брать из мета-тега description страницы.
В качестве "подопытного кролика" я выбрал портал АльфаКМВ. Этот ресурс имеет в своем составе немногим более 3000 страниц разной вложенности в папках и можно спокойно оценить скорость работы нашей поисковой системы.
1. Способ первый: использование встроенных функций
Хоть MySQL считается не особо "навороченной" базой данных (хотя я лично так не считаю), у неё есть неоспоримые плюсы - это простота использования, а основной, в нашем случае, индекс FULLTEXT, который без особых сложностей организует нам прекрасный поиск. нужно просто приложить к этому небольшие усилия:
1.1. Организация таблицы
Индексная таблица состоит всего из четырех полей - ссылка на страницу (url), заголовок страницы (title), описание страницы (description) и текстовая часть (полнотекстовый индекс):
CREATE TABLE `search` (
`url` varchar(250) NOT NULL,
`title` text NOT NULL,
`description` text NOT NULL,
`search` text NOT NULL,
PRIMARY KEY (`url`),
FULLTEXT KEY `s` (`search`)
) TYPE=MyISAM;
1.2. Рекурсия
Вторым этапом нам нужно пройтись по всем папкам и файлам сайта для индексации, для чего воспользуемся рекурсией.
...
Рекурсия - вызов функции или процедуры из неё же самой (обычно с другими значениями входных параметров), непосредственно или через другие функции (например, функция А вызывает функцию B, а функция B - функцию A). Количество вложенных вызовов функции или процедуры называется глубиной рекурсии.
...
Следует избегать избыточной глубины рекурсии, так как это может вызвать переполнение стека.
...
Задумчиво, но так как мы не знаем глубину папок в которых могут лежать файлы сайта, то прийдется использовать её, хотя можно поискать на CPAN, но мне кажется, это лишняя трата времени, быстрее написать самому.
Создаем скрипт, который будет индексировать наш сайт, назовем его index.pl.
#!/usr/bin/perl
# Подключаем основные модули
use strict;
use warnings;
use DBI;
# "Локаль" - обязательно, т.к. кириллицу мы будем использовать и в регах
use locale;
use POSIX qw(locale_h);
setlocale(LC_CTYPE, 'ru_RU.CP1251');
setlocale(LC_ALL, 'ru_RU.CP1251');
# Обозначаем глобальные переменные
use vars '$dbh', '$url_start', '$dir_start', '@dir_filter', '@file_type';
# Директория DocumentsRoot сайта
$dir_start = '/var/www/my_sites/html';
# Домен сайта
$url_start = '//www.my_sites.ru';
# Фильтр директорий (директории, которые исключаются из индексации)
@dir_filter = (
'cgi-bin',
'images',
'temp',
);
# Фильтр файлов (какие расширения файлов индексировать)
@file_type = (
'shtml',
'html',
'htm',
);
# Сразу отправляем заголовок браузеру
print "Content-type: text/html; charset=windows-1251\n\n";
# Открываем временный файл для хранения данных
open (TMP, '>>', '/var/www/my_sites/cgi-bin/search/search.txt');
flock (TMP, 2);
# Передаем управление процедуре рекурсии
&recursion();
# Закрываем временный файл
close TMP;
&update_db;
print 'Индексация завершена!';
exit;
sub recursion {
# Получаем текущую директорию рекурсии относительно DocumentsRoot
my $postfix = shift || undef;
# Формируем абсолютный путь текущей директории
my $dir = $dir_start.($postfix || '');
# Объявляем локальным переменные FOLDER (в основном нам нужен дескриптор*)
local *FOLDER;
# Открываем директорию
opendir (FOLDER, $dir);
# И последовательно считываем
while (my $item = readdir FOLDER) {
# "отсекаем" элементы '.' и '..' что бы не "выскочить" на директорию выше
next if $item eq '.' || $item eq '..';
# Определяем относительный путь
my $path = ($postfix || '').'/'.$item;
# Если элемент списка - директория, то порождаем процедуру вглубь рекурсии
&recursion($path) if -d $dir.'/'.$item && !map {$path =~ /^\/$_/} @dir_filter;
# Если элемент списка - файл, то передаем относительный путь к нему в процедуру обработки
&file_parse($path) if -f $dir.'/'.$item && map {$path =~ /\.$_$/} @file_type;
}
# Закрываем директорию
close FOLDER;
# ... и возвращаемся
return 1;
}
Как видно - никаких сложностей. Однако хочу заметить, что в глубь рекурсии мы уходим только для директорий, а не символьных ссылок, причем, я бы и не рекомендовал использовать символьные ссылки, чтобы рекурсия не зациклилась во время обработки.
1.3. Предварительное формирование данных или просто формирование данных
Третий этап - подготовка файла и индексации. Так как очень часто на страницах сайта используются SSI внедрения, то их нужно будет включить в основное тело страницы.
...
в одном разделе сайта дизайнер внедрил красивый заголовок через SSI, когда поисковая система проиндексировала страницы, то ключевые слова заголовка были пропущены, и поиск осуществлялся "криво"
...
sub file_parse {
# Получаем относительный путь к файлу
my $file = shift;
# Открываем файл страницы
open (FILE, "$dir_start$file");
# Объявляем переменную в которой бодем собирать контент
my $content;
# Построчно производим обработку
while (<FILE>) {
$_ =~s /<!--#include virtual="(.*?)"-->/&_include_ssi($file ,$1)/eg;
if ($content) {$content .= $_} else {$content = $_}
}
# Закрываем файл страницы
close FILE;
# Обработка контента
# Убираем "жесткие" пробелы и пробельные символы
$content =~s /\ / /gi;
$content =~s /[\s\t\r\n]/ /gi;
# Выбираем заголовок и описание страницы
my ($title) = $content =~ /<title>(.*)<\\title>/i;
my ($description) = $content =~ /<meta.*description.*content=(.*?)>/i;
# Производим "чиску" контента оставляя только символы
$content =~s /[^\w\-\s]/ /g;
$content =~s /\s{2,}/ /g;
# Отправляем обработанный контент, путь, заголовок и описание в процедуру обновления БД
&update_data(\$content, $title, $description, $file);
return 1;
}
sub _include_ssi {
# Получаем имя HTML файла и имя файла SSI
my ($file, $ssi) = @_;
# Объявляем переменную - путь к файлу внедряемому через SSI
my $path;
# Если файл берется из корня
if ($ssi =~ /^[\\\/]{2}/) {
$path = $dir_start.$ssi;
# "Чистим" двойные "слеши"
$path =~s /([\\\/]){2,}/$1/g;
# Иначе
} else {
# Определяем директорию основного файла
my ($path) = $file =~ /(.*)[\/\\].*?/;
if ($path) {$path .= $ssi} else {$path = $ssi}
# "Чистим" двойные "слеши"
$path =~s /([\\\/]){2,}/$1/g;
}
# считываем контент файла
open (SSI, $path);
my $content = join('', <SSI>);
close SSI;
# Возвращаем контент файла
return $content
}
В данной процедуре, производится обработка контента файла. Хочу заметить, что SSI я обрабатываю только для директивы include virtual, при этом не проверяю внедряемый файл, если же через include virtual внедряются скрипты или используются дополнительные директивы, то данный код нужно будет соответственно доработать. Так же может возникнуть вопрос, почему я разбиваю скрипт на такие маленькие процедуры, когда, по большому счету, достаточно было бы описать это в одной процедуре - все это только лишь для того что бы облегчить понимание предмета, а последнее вынесение процедуры update_data - потому что дальше способы индексации разнятся между собой.
1.4. Обновление блока данных
В общем, в эту процедуру мы передаем уже практически готовые данные для вставки в базу данных, поэтому:
Для варианта с LOAD DATA:
sub update_data {
# Получаем данные
my ($content, $title, $description, $file) = @_;
# Формируем строку
my $line = $url_start.$file."\t".$title."\t".$description."\t".$$content."\n";
# Записываем строку во временный файл
print TMP $line;
return 1;
}
для варианта с INSERT INTO:
sub update_data {
# Получаем данные
my ($content, $title, $description, $file) = @_;
# Формируем запрос
my $update = "INSERT INTO wm5_search_one
SET
url = '$url_start$file',
title = '$title',
description = '$description',
search = '$$content'
";
# Выполняем запрос к БД
$dbh->do($update);
return 1;
}
Правда, во втором варианте нужно не забыть предварительно подключится к базе данных.
1.5. Обновление базы данных
Можно рассмотреть два варианта обновления данных:
Если мы обновлять данные будем с помощью LOAD DATA. Информация уже сформирована и требуется только обновить базу данных:
sub update_db {
# Подключаемся к базе данных
$dbh = 'DBI'->connect('DBI:mysql:database=search;host=localhost;port=3306', 'user', 'password')
or die $DBI::errstr;
# Обнуляем таблицу
$dbh->do('DELETE FROM search;')
or die $DBI::errstr;
# Загружаем данные
$dbh->do('LOAD DATA INFILE "/var/www/my_sites/cgi-bin/search/search.txt" INTO TABLE search;')
or print "ERROR!!! $DBI::errstr <br>\n";
# Отключаемся от базы данных
$dbh->disconnect();
# Удаляем временный файл
unlink '/var/www/my_sites/cgi-bin/search/search.txt';
1;
}
Хочу обратить внимание на то что я указываю абсолютные пути к временному файлу. Это условие обязательное, так как скрипт рассчитывается на запуск с помощью cron.
Теперь рассмотрим особенности обновления данных, с помощью INSERT, и с помощью LOAD DATA. Довольно противоречивое мнение у меня сложилось по поводу выбора способа обновления. С одной стороны команда INSERT очень медленная, но с другой, тратится меньше ресурсов. Я протестировал оба варианта, благо изменения скриптов для этого не большие (вместо дописывания данных во временный файл вставляем запись в таблицу, а процедуру обновления базы данных опускаем). Итак, что получилось:
Тестирование производилось, на одном и том же сайте но на разных серверах (более и менее мощном), сайт все тот же ~3000 статичных страниц:
Более мощный сервер - P4 2.8 (HyperThreading), 800 Mhz FSB, память двухканальная 400 Mhz Kingston 512 MB, Promise UltraDMA133, 2 х 40Gb (Seagate Barracuda) зеркало (на нем сайт) и еще 120 Gb (Maxtor) SATA (на нем ядро SuSE 9.2, MySQL 4.0.18).
-
При использовании INSERT индексация производилась в течение 130-140 секунд объем данных таблицы 105'961'780 байт;
-
При использовании LOAD DATA индексация производилась в течение 110-120 секунд (40-50 секунд - формирование временного файла, 60-70 секунд обновление базы данных), размер временного файла - 106'216'954, объем данных таблицы - тот же;
Прирост производительности не большой - 15%, но во время обновления базы данных сама база находилась "в трансе", т.е. другие обращения к базе данных происходили с большой задержкой. Отсюда можно сказать - быстрее, но не рациональнее.
Более слабый сервер - P4 2.4, 533 Mhz FSB, память 333 Mhz 1024 MB, 20 Gb (Samsung 7200) на нем ядро Red Hat 7.3, MySQL 4.0.18 и сайт.
-
При использовании INSERT индексация производилась в течение 600-900(!) секунд объем данных таблицы 105'961'780 байт;
-
При использовании LOAD DATA индексация производилась в течение 250-300 секунд (100-120 секунд - формирование временного файла, 150-200 секунд обновление базы данных), размер временного файла - 106'216'954, объем данных таблицы - тот же;
Конечно, большой разброс по времени дало количество текущих процессов (видимо сказалось отсутствие HyperThreading), но результат показывает, что прирост производительности составил, как минимум 100%, и хотя база данных была дольше "в трансе", но не в таком глубоком (почему - сложно сказать конфиги MySQL идентичны, может большее количество оперативной памяти сказалось).
Итак - решать Вам по какому пити идти, все зависит от сервера, его возможностей и ограничений.
1.6. Скрипт вывода результатов поиска
Вот теперь самое интересное, зачем мы собственно делали столько манипуляций. Я не буду особо расписывать данный скрипт: формировать постраничный вывод, "наводить красоту" и так далее... просто сделаю скелет:
#!/usr/bin/perl
# Подключаем основные модули
use strict;
use warnings;
use DBI;
use CGI qw(param);
use locale;
use POSIX qw(locale_h);
setlocale(LC_CTYPE, 'ru_RU.CP1251');
setlocale(LC_ALL, 'ru_RU.CP1251');
# Получаем поисковый запрос
my $search = param('search') || undef;
# Сразу отправляем заголовок браузеру
print "Content-type: text/html; charset=windows-1251\n\n";
# Форма запроса
print '<form action='' method=get>';
print '<input type=text name=search value="'.($search || '').'">';
print '<input type=submit value=search>';
print '</form>';
# Если запрос пустой, то останавливаем скрипт
unless ($search) {print 'Результатов запроса - 0'; exit}
# На всякий случай "чистим" полученные данные
$search =~s /[^\w\s\-]/ /g;
# "Сжимаем" пробельные символы
$search =~s /\s+/ /g;
# Подключаемся к базе данных
my $dbh = 'DBI'->connect('DBI:mysql:database=search;host=localhost;port=3306', 'user', 'password')
|| die $DBI::errstr;
# Формируем запрос
my $sql = "SELECT
url, title, description,
MATCH (search) AGAINST ('$search') AS score
FROM search
WHERE MATCH (search) AGAINST ('$search')
LIMIT 50";
my $sth = $dbh->prepare($sql);
$sth->execute() || die $DBI::errstr;
# Устанавливаем счетчик
my $i = 1;
while (my $row = $sth->fetchrow_hashref()) {
# Печатаем строку результата
print $i, ' - <a href="', $$row{'url'}, '">', $$row{'title'}, '<a><br>',
$$row{'description'}, '<br><br>';
$i++
}
$sth->finish();
# Отключаемся от базы данных
$dbh->disconnect();
if ($i == 1) {print 'Результатов запроса - 0'}
else {print 'Результатов запроса - ', $i - 1}
exit;
Практически наш скрипт готов. Он прекрасно отрабатывает полнотекстовый поиск, при этом без особых сложностей.
1.7. Дополнительные возможности
Для начала, (хотя это нужно было сделать в самом начале) ознакомимся с документацией MySQL - <6.8. Полнотекстовый поиск в MySQL> в данном документе сказано, что существует возможность усложнения поискового запроса по индексу, то есть определить "вес" слов, а так же использовать их "усечение". Доработав немного скрипт поиска можно создать "сносную" поисковую машину, которая учитывает морфологию. Для этого сделаем следующее:
а). в переменной поискового запроса заменим два-три последних символа в каждом слове, а так же добавим разрешенные символы:
...
$search =~s /[^\w\d\s\-\"\+\~\<\>]/ /g;
# "Сжимаем" пробельные символы
$search =~s /\s+/ /g;
$search =~s /([\w\d\-]+)[\w\d\-]{2}/$1\*/g;
$search =~s /\s\*\s/ /g;
...
б). в запросе к базе данных укажем IN BOOLEAN MODE:
...
my $sql = "SELECT
url, title, description,
MATCH (search) AGAINST ('$search' IN BOOLEAN MODE) AS score
FROM search
WHERE MATCH (search) AGAINST ('$search' IN BOOLEAN MODE)
LIMIT 50";
...
Но, хочу сразу оговорится: при использовании BOOLEAN MODE на редкость плохо считается релевантность* и результаты запроса не сортируются, поэтому использовать эту функцию - IMHO не стоит. И на помощь приходит "солдатская смекалка", что нам мешает во время индексации формировать двойной контент с полными словами и с "обрезанными" и так же расширить подобным образом запрос?
а). в скрипте индексации, после "чистки" контента файла:
...
my $content2 = $content;
$content2 =~s /([\w\-]+)[\w\-]{2}/$1/g;
$content2 =~s /\s[\w\-]\s/ /g;
$content .= $content2;
...
б). в поисковом скрипте, после "передачи" формы:
...
my $search2 = $search;
$search2 =~s /([\w\-]+)[\w\-]{2}/$1/g;
$search2 =~s /\s[\w\-]\s/ /g;
$search .= ' '.$search2;
...
И "о чудо!!!" скрипт начал искать, то что раньше его было не заставить. Конечно имеет смысл еще "поиграть" с количеством обрезаемых символов в словах и формировать не "двойной" поисковый запрос, а "тройной" и более... но это дело техники...
Так же, не нужно забывать о том, что именно ищут пользователи на Вашем сайте. Для того, что бы это определись, достаточно сохранять поисковые запросы пользователей, а потом анализировать их. В соответствии с анализом корректировать контент на страницах для более "правильного" поиска (например: пришлось включить в контент страниц слово "анегдот", потому как половина пользователей искала именно его).
*ПРИМЕЧАНИЕ: Это не написано в официальной документации, но как показывает практика, при использовании IN BOOLEAN MODE, отключается критерий поиска фразы, то есть, если в поисковом запросе несколько слов, то они ищутся не как фраза, а каждое слово отдельно, при этом совпадение слова определяется как 1, коэффициент релевантности в итоге получается целое число, варьировать дробной частью которого возможно только "весом" слов, что не приемлемо для большинства пользователей.
1.8. "Грабли", "подводные камни" и немного об оптимизации
К сожалению, рассказать обо всех нюансах я просто не в состоянии, на это не хватит времени, но какие-то основные описать могу:
-
кодировка в базе данных, по умолчанию у меня стоит всегда cp1251, возможно поэтому я не испытывал особо трудностей во время поисков, менять на другую кодировку ради проверки - я не стал;
-
кодировка (локализация) в скрипте CP1251, не всегда эта кодировка по умолчанию установлена на сервере, если будет наблюдаться не адекватное поведение, то её требуется проверить (вообще, насчет кодировки cp1251 - это не панацея, просто я использую её);
-
полнотекстовый индекс по умолчанию индексирует слова размером более 3-х символов (слова из 3-х символов - не индексируются). Если требуется индексировать слова менее 4-х символов, то нужно будет настроить конфиг MySQL, как это сделано, прекрасно описано в главе < 6.8.2. Тонкая настройка полнотекстового поиска в MySQL>. В связи с этим можно так же исключать из поля search таблицы слова размер которых менее индексного, для экономии места;
Вот, собственно, и все, просто и компактно. Пора заняться настоящим "весельем"... :-)
2. Способ второй: "Изобретаем велосипед" или "Пляски с бубнами"
... А в PostrgeSQL FULLTEXT нету :(... (Цитата из ЖЖ)
Достаем из тумбочки старый любимый бубен, разжигаем костер и начинаем готовится к пляске.
Сразу хочу сказать, что данное решение мне нравится больше:
- во-первых - используются стандартные инструменты, что позволяет сделать поисковую систему максимально кроссплатформенной;
- во-вторых - возможность более "тонкой" настройки поисковой системы в целом и в частности.
По каким критериям производится поиск по сайту:
- совпадение слова - это само собой;
- "вес" слова на страницы, то есть количество повторов слова на странице.
При этом я совершенно не учитываю расположение слова на странице и то, находятся ли поисковые слова рядом, или же в разных частях документа. С одной стороны - это плохо, но с другой - мы же не пишем поисковую систему Google, нам нужно найти что-либо в пределах одного сайта, поэтому излишние критерии релевантности - ни к чему, только лишняя головная боль и бесполезная трата ресурсов.
Для нашей поисковой системы нужно будет создать три таблицы:
-
слова (search_main) - таблица в которой хранятся (раздельно!) все поисковые слова сайта, страница к которой они относятся и их вес;
-
страницы (search_page) - URL, заголовки и описания страницы. Хотя возможно эти данные хранить применительно к каждому поисковому слову, но это тоже лишняя трата ресурсов;
-
фильтр (search_filter) - список слов не включаемых в поисковые - это имена стилей, некоторые теги, операторы JavaScript; в общем, те слова, которые не требуются для поиска.
2.1. Организация таблиц
Структура таблиц и связей выглядит так:

Команды на создание таблиц:
CREATE TABLE `search_filter` (
`word` varchar(100) NOT NULL,
`note` varchar(100) NULL,
PRIMARY KEY (`word`)
) TYPE=MyISAM;
CREATE TABLE `search_main` (
`word` varchar(100) NOT NULL default '',
`page` int(11) NOT NULL default '0',
`relevance` int(11) NOT NULL default '0',
KEY `word` (`word`,`page`)
) TYPE=MyISAM;
CREATE TABLE `search_page` (
`id` int(11) NOT NULL,
`url` varchar(200) NOT NULL default '',
`title` varchar(200) NOT NULL default '',
`description` text NOT NULL,
PRIMARY KEY (`id`)
) TYPE=MyISAM;
2.2. Предварительное формирование данных или просто формирование данных
Не будем возвращаться к рекурсии и обработке файла, так как они идентичны (о чем было сказано выше).
Итак, что мы должны сделать в этой процедуре. Контент практически подготовлен, нужно сформировать 2 блока (файла) данных. Для этого в самом начале скрипта откроем для последовательной записи (если они не были заранее очищены, то их очищаем) и выберем слова исключения (search_filter). Так же в начале скрипта мы определяем глобальную переменную $i =1 которая будет у нас идентификатором страницы, вот почему мы не указали при создании таблиц автоматических счетчиков. Объясняю почему:
-
во-первых, данные вставляются в базу данных не сразу, а после обработки всей информации, а нам нужно будет сразу определять связь слово->страница;
-
во-вторых, даже при последовательном внесении информации в базу данных, прийдется делать дополнительный запрос для определения последнего идентификатора страницы;
-
в-третьих, таблица базы данных пустая, и за уникальность идентификаторов можно не волноваться.
#!/usr/bin/perl
# Подключаем основные модули
use strict;
use warnings;
use DBI;
use locale;
use POSIX qw (locale_h);
setlocale(LC_CTYPE, 'ru_RU.CP1251');
setlocale(LC_ALL, 'ru_RU.CP1251');
# Обозначаем глобальные переменные
use vars '$dbh', '$url_start', '$dir_start', '@dir_filter', '@file_type', '$i', '%filter';
# Инициализируем идентификатор страниц
$i = 1;
# Директория DocumentsRoot сайта
$dir_start = '/var/www/sites/alfakmv/html';
# Домен сайта
$url_start = '//www.alfakmv.ru';
# Фильтр директорий (директории, которые исключаются из индексации)
@dir_filter = (
'cgi-bin',
'images',
'temp',
);
# Фильтр файлов (какие расширения файлов индексировать)
@file_type = (
'shtml',
'html',
'htm',
);
# Коннектимся
$dbh = 'DBI'->connect('DBI:mysql:database=search;host=localhost;port=3306', 'user', 'pass')
|| die $DBI::errstr;
# Выбираем слова - исключения
my $sql = 'SELECT word FROM search_filter';
my $sth = $dbh->prepare($sql);
$sth->execute() || die $DBI::errstr;
while (my $row = $sth->fetchrow_hashref()) {$filter{$$row{'word'}} = 1}
$sth->finish();
# Очищаем таблицы базы данных
$dbh->do('DELETE FROM search_main');
$dbh->do('DELETE FROM search_page');
# Сразу отправляем заголовок браузеру
print "Content-type: text/html; charset=windows-1251\n\n";
open (WORDS, '>>', '/var/www/my_sites/cgi-bin/search/words.txt');
flock WORDS, 2;
open (PAGES, '>>', '/var/www/my_sites/cgi-bin/search/words.txt');
flock PAGES, 2;
# Передаем управление процедуре рекурсии
&recursion();
close PAGES;
close WORDS;
&update_db;
exit;
2.3. Обновление блока данных
Определим основные действия процедуры:
- сформировать строку для блока данных страниц, и записать её в файл;
- обработать контент страницы, подсчитать вес слов и сформировать список;
- дописать список в блок данных (файл) слов;
sub update_data {
# Получаем данные
my ($content, $title, $description, $file) = @_;
# Формируем строку блока данных страниц и записываем её в файл
my $line = $i."\t".$url_start.$file."\t".$title."\t".$description;
print PAGES $line, "\n";
# Переводим текст, контент страницы, в нижний регистр
$$content =~tr /A-Z\xA8\xC0-\xDF/a-z\xB8\xE0-\xFF/;
# Определяем хеш для подстчета веса слов
my %words;
foreach my $word (split(' ', $$content)) {
# Фильтрация слов
next if length $word < 3; # Примечание*
next if exists $filter{$word};
# Формируем хеш слов и их вес
if (exists $words{$word}) {$words{$word}++} else {$words{$word} = 1}
}
# Формируем строки блока данных слов
foreach my $word (keys %words) {
my $line = $word."\t".$i."\t".$words{$word};
print WORDS $line, "\n";
}
# Обновляем идентификатор страницы
$i++;
return 1;
}
*ПРИМЕЧАНИЕ: Цифра 3 как раз и отвечает за размер слова, которые разрешены для индексации
2.4. Обновление базы данных
Данная процедура просто выгружает в базу данных наши два файла, после чего их удаляет
sub update_db {
# Загружаем данные
$dbh->do("LOAD DATA INFILE \"/var/www/sites/alfakmv/cgi-bin/search2/words.txt\" INTO TABLE search_main;")
|| die "ERROR!!! $DBI::errstr <br>";
$dbh->do("LOAD DATA INFILE \"/var/www/sites/alfakmv/cgi-bin/search2/pages.txt\" INTO TABLE search_page;")
||
die "ERROR!!! $DBI::errstr <br>";
# Удаляем временные файлы
unlink '/var/www/sites/alfakmv/cgi-bin/search2/words.txt';
unlink '/var/www/sites/alfakmv/cgi-bin/search2/pages.txt';
return 1;
}
Правда еще хотел оговориться, что при индексации формируются файлы по объему соразмерные с объемом текстовой части сайта, поэтому могут возникнуть проблемы с лимитом дискового пространства на хостинге.
На этом, с индексацией все. Я даже не рассматриваю варианты обновления данных с помощью команд LOAD DATA и INSERT так как, в таблицу слов вставляется записей не на один порядок больше чем в первом варианте с FULLTEXT (~3000 против ~2000000), а таблицу страниц - ровно такое же количество, правда в гораздо меньшем объеме.
2.5. Скрипт вывода результатов поиска
В данный скрипт особо не отличается от скрипта первого варианта, единственное радикальное различие - запрос к базе данных, он более сложный, так как выборка производится из двух таблиц, условие основано на списке слов поискового запроса и прочие мелочи...
#!/usr/bin/perl
# Подключаем основные модули
use strict;
use warnings;
use DBI;
use CGI qw(param);
use locale;
use POSIX qw(locale_h);
setlocale(LC_CTYPE, 'ru_RU.CP1251');
setlocale(LC_ALL, "ru_RU.CP1251");
# Получаем поисковый запрос
my $search = param('search') || undef;
# Сразу отправляем заголовок браузеру
print "Content-type: text/html; charset=windows-1251\n\n";
# Форма запроса
print '<form action='' method=get>';
print '<input type=text name=search value="'.($search || '').'">';
print '<input type=submit value=search>';
print '</form>';
# Если запрос пустой, то останавливаем скрипт
unless ($search) {print 'Результатов запроса - 0'; exit}
# На всякий случай "чистим" полученные данные
$search =~s /[^\w\s\-]/ /g;
# "Сжимаем" пробельные символы
$search =~s /\s+/ /g;
# Подключаемся к базе данных
my $dbh = 'DBI'->connect('DBI:mysql:database=search;host=localhost;port=3306', 'root', 'dfkmrbhbz')
|| die $DBI::errstr;
# Формируем запрос
my @search = split(' ', $search);
my $sql = "SELECT
t2.url, t2.title, t2.description, SUM(t1.relevance) AS score
FROM search_main AS t1, search_page AS t2
WHERE t1.word IN ('".join("','",@search)."') AND t1.page = t2.id
GROUP BY t1.id
ORDER BY score DESC
LIMIT 50";
my $sth = $dbh->prepare($sql);
$sth->execute() || die $DBI::errstr;
# Устанавливаем счетчик
my $i = 1;
while (my $row = $sth->fetchrow_hashref()) {
# Печатаем строку результата
print $i, ' - <a href="', $$row{'url'}, '">', $$row{'title'}, '<a><br>',
$$row{'description'}, ' - ', $$row{'score'},'<br><br>';
$i++
}
$sth->finish();
# Отключаемся от базы данных
$dbh->disconnect();
if ($i == 1) {print 'Результатов запроса - 0'}
else {print 'Результатов запроса - ', $i - 1}
exit;
Вот и все, совсем все, осталось сравнить эти 2 способа.
3. Сравнение
Сравнение проводилось на одном и том же сервере, индексировался один и тот же сайт.
|
|
С использованием FULLTEXT
|
Ручная обработка |
| Объем занимаемых данных (относительно друг друга) |
1 |
0,43 |
Скорость индексации
(относительно друг друга, средняя величина, индексация с помощью команды FULLTEXT) |
1 |
0,97 |
| Скорость поискового запроса к базе данных |
0,02 сек
(~3 300 записей) |
0,31 сек
(~2 300 000 записей) |
В итоге мы видим, что несмотря на то что объем данных во втором способе гораздо меньше (индекс FULLTEXT довольно объемный), скорость индексации отличается незначительно (если совсем не отличается), а вот запрос для выборки результатов гораздо медленнее. Это связано с гораздо большим количеством записей, и более сложным запросом из двух таблиц. Можно, конечно, во втором способе данные о странице хранить в основной таблице, но при этом объем данных увеличивается в 5-6 раз, а скорость запроса убыстряется всего на 10-15 %, что, впрочем, не актуально. Впрочем, для небольших сайтов оба варианта будут одинаково приемлемы, так как все таки тестирование проводилось на сайте, имеющем более 3000 статичных страниц.
При этом результаты выполнения запроса практически идентичны в обоих случаях, различие было только в порядке вывода (релевантности), что никак не сказывалось на правильности поиска.
Заключение
Итак мы рассмотрели 2 способа организации поиска по сайту. Следует иметь в ввиду, что поиск осуществляется по статичным страницам сайта и никак не предназначен для динамичных сайтов. Естественно были рассмотрены практически идеальные варианты построения сайта:
- не учтена возможность существования символьных ссылок;
- не учтены вариации метатегов title и description;
- не учтены вариации использования SSI;
- не учтена возможность создания фильтров для определенных файлов (кроме как по расширению);
- не учтена возможность создания фильтров для определенных вложенных папок (кроме как корневых);
- может что-то еще не учтено :)...
но, впрочем, скелет дан, нарастить мясо - на совести программиста...
Томулевич Сергей (aka Phoinix) 11.08.2005 г.
|