Поиск по сайту - нет ничего проще.
Для чего нужен поиск?
Удобство работы с Вашим сайтом и легкость при поиске нужной информации на нем
являются важным моментом в процессе привлечения и удержания посетителей на сайте.
Как известно, неудобство всегда отталкивает. И напротив, если посетителю будет легко и
удобно работать с Вашим информационным ресурсом, то у него сложится хорошее мнение о сайте (и об его авторах) и он обязательно
вернется через некоторое время.
Особенно остро стоит проблема быстроты и удобства поиска нужной информации, когда сайт
содержит большие обьемы информации. В этом случае хорошим решением может оказаться использование
поискового запроса по интересующей теме на сайте. Чтобы осуществить поиск по своему
сайту Вам нужно использовать специальные скрипты (Perl, Php, ASP). Кроме того, что Вам потребуется
знание и умение писать программы для одного из этих скриптов, также необходимо иметь
возможность запускать их на выполнение. Как правило, можно использовать такие
скрипты для работы сайта как при платном, так и бесплатном хостинге.
Программы.
Для этой цели существует масса программ и скриптов, есть платные, есть
бесплатные. Вот их, неполный, список:
Мы будем пользоваться последней программой. Почему? Вот причины, по которым она мне
понравилась больше других:
- Мне удалось запустить ее с первого раза;
- На настройку ушло менее 5 минут;
- Работает 100% автономно, не требует ни PHP, ни Perl. Даже не использует СУБД (MySql, PostgreSql, Oracle и др).
Но есть и недостатки:
- Программа платная (мы то с вами знаем, что это не недостаток, уже привыкли);
- Нет возможности обновить поисковый индекс (при менее 10 тыс документов это тоже не проблема).
Как работает поиск.
Первое, что необходимо усвоить - это то, что, при нажатии на кнопку "Искать" поиск
производится не по страницам сайта, а по специальной базе данных - поисковому
индексу.
Собственно, по этой причине установка поискового механизма состоит из двух частей:
- Индексация - построение поискового индекса;
- Установка фронтенда - системы быстрого поиска по индексу.
А теперь более подробно, по шагам.
Шаг 1 - где взять программу.
Программу можно взять по адресу //www.cn-software.com/download.xhtm. На момент
написания статьи доступна последняя версия - CNSearch Pro 1.2
Уже на этой стадии Вам необходимо определиться, из под какой операционной системы
будт произведена индексация, и какая операционная система установлена на том
сервере, где будет установлен фронтенд.
Я производил индексацию со своего домашнего компьютера - по модему :) (из под
Windows 2000), а фронтенд устанавливал на сервере ValueHost (операционная система
FreeBSD 4.X)
Для распаковки я воспользовался архиватором WinRar (www.rarlab.com) - он
успешно справился как с ZIP, так и с TAR.GZ архивами.
Шаг 2 - индексация.
После распаковки переходим в каталог "indexer" и настраиваем конфигурационный файл. У
меня он получился такой:
1. [Job localhost]
2. [Index]
3. URL //fantasy.ok.nov.ru/
4. Statistic Append
5. CharSet ByHTTPHeader
6. MaxFiles 300
7. Exclude .gif,.jpg
8. [Job ludok]
9. [Index]
10. URL //lud.ok.nov.ru/
11. Statistic Append
12. CharSet ByMetaTag
13. MaxFiles 3000
Описание всех параметров можно найти в мануале, который включен в дистрибутив. (Правда
он на английском языке, но я разобрался и без знания оного).
Конфигурационный файл содержит две задачи, первая с названием fantasy, а вторая -
ludok. (Строки 1 и 8). Каждая задача содержит по одному действию - [Index] (строки 2 и
9)
Для первой задачи в строке 3 задается стартовый адрес, именно с него начнется обход
сайта. В строке 4 указан параметр "Statistic Append", который говорит о
том, что созданный после индексации отчет необходимо дописать в
файл stats.log (может принимать значения "No" - не создавать отчета
вообще, и "Overwrite" - перезаписать старый файл).
В строке 5 указан способ определения кодировки, возможны следующие варианты:
- ByMetaTag - определять кодировку по тегу META content="charset".
- ByHTTPHeader - определять кодировку по полю Content-Type HTTP заголовка,
если поле не содержит информации о кодировке, то производится попытка
определит ее по META тегу, если и там нет ни какой информации, то система
считает, что кодировка windows-1251
- win-1251 - Не определять кодировку, считать, что кодировка windows-1251
- koi8-r - Не определять кодировку, считать, что кодировка koi-8
Из всего перечисленного пробовал только первые два пункта, проблем не возникло ни с
тем, ни с тем. В строке 6 указано максимальное количество файлов, если файлов больше 300, то они не
добавляются в поисковый индекс.
Ну и, наконец, в строке 7, через запятую, указаны исключения. Если имя файла содержит
подстроку ".jpg" или ".gif", то они не индексируются. На самом деле, эта строка не несет
никакой полезной нагрузки, так как индексатор сам определит, что jpeg и gif файлы даже
скачивать не стоит.
Файл создали - теперь запустим сам индексатор и посмотрим, что он нам скажет:
C:cntestwindowsindexerindexer.exe fantasy
CNSearch ver.1.2 [build 4564]
Compiled Sat Nov 16 19:48:35 2002 under Microsoft Windows 2000 [Версия
5.00.2195]
Rebuilding URL list...Loading library: RTF (Rich text format)
Loading library: TXT (Plain text)
Loading library: DOC (Microsoft Word document format)
Loading library: XLS (Microsoft Excel document)
Loading library: MP3 (MPEG Layer 3 Audio)
Domain: fantasy.ok.nov.ru
[1/1] //fantasy.ok.nov.ru [200:9454]..Ok
[2/14] //fantasy.ok.nov.ru/news.htm [200:8738]..Ok
[3/15] //fantasy.ok.nov.ru/arda.htm [200:6278]..Ok
...
[32/34] //fantasy.ok.nov.ru/files/mmc.exe [302:268]
[33/34] //fantasy.ok.nov.ru/peoples/index.htm [200:13960]..Ok
[34/34] //fantasy.ok.nov.ru/peoples/asasd [200:13964]..Ok
О содержимом этих строчек ничего не сказано ни в readme.txt, ни в мануале, но я так
полагаю, что две первые цифры в квадратных скобках - это, соответственно, порядковый
номер документа и количество документов в очереди.
Потом идет URL индексируемой страницы, и опять в квадратных скобках код ответа
сервера (200 Ok, 404 Not Found и т.д.) и размер индексируемого документа.
После того, как indexer закончит свою работу, Вы сможете увидеть четыре или пять
файлов с расширением .cns:
- index.cns
- giles.cns
- fulltxt.cns
- doc.cns
- stats.cns
Файл stats.cns я сразу удалил и больше о нем не вспоминал. Он содержал отчет о
произведенной индексатором работе, а все остальные переместил в каталог cgi-bin на
своем сервере.
Шаг 4 - Настройка Фронтенда
Теперь, из скачанного дистрибутива для FreeBSD я распакавал два файла:
freebsdfrontendsearch
freebsdfrontendsearch.htm
Первый - это откомпилированная программа поиска, а второй файл - это шаблон
поисковой страницы. Эти файлы я тоже скопировал в каталог cgi-bin, и файлу search
установил права на запуск (Для этого в FAR'e (www.rarlab.com) при соединении по
FTP я нажал Сtrl-A и поставил галочку напротив первого "X")
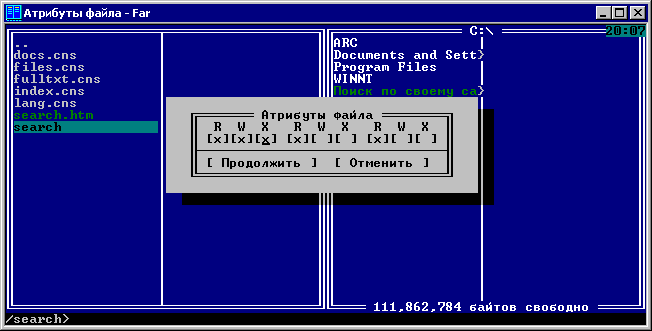
После этого осталось только исправить файл search.htm, а при знании HTML - это дело
техники.
Шаг 5 - тестирование системы
И наконец - тестовый поиск:
//www.вашсервер.ru/cgi-bin/search?q=тест
Вот что у меня получилось:
//search.novgorod.ru/search.php?q=%F2%E5%F1%F2&where=1
Список сайтов, по которым производится поиск можно посмотреть на
этой странице: //search.novgorod.ru/searchat/
|