
 || разделы:: || разделы:: | |
| || поиск по сайту:: | |
| || реклама:: |
|
| || новости почтой:: |
|
| Популярные статьи |
|
| Hot 5 Stories |
|
| || рекомендуем:: | |
| |
Введение в XML
В этой статье будут подробно описаны основы синтаксиса популярного сейчас
языка разметки XML. Также здесь будут упомянуты существенные аспекты базового
документа XML.
Данная статья открывает серию статей, посвященных основам написания документов
XML, принципам оформления этих документов, способам отображения XML документов
в браузере.
Язык разметки XML описывает, а также структурирует содержание файла XML. Основа
языка разметки – тэг, который ограничивает разделы содержания. Данный способ
описания документа очень похож на разметку HTML, однако между этими языками
существует большая разница.
Приведем небольшой пример, написанный как на HTML, так и на XML.
Пусть у нас есть небольшая таблица, в одной из ячеек которой помещен некоторый
текст.
|
HTML
|
XML
|
|
<Table border=0>
<tr>
<td>
<H1 align=”center”>Этот текст находится внутри HTML</h1>
<hr size=1>
</td>
</tr>
</table>
|
<table border=”0”>
<tr>
<td>
<h1 align=”center”>Этот текст находится внутри XML</h1>
<hr size=”1”/>
</td>
</tr>
</table>
|
Теперь, взглянув на эти примеры, можно заметить отличия разметки XML от привычного
нам HTML. Главное отличие состоит в том, что язык XML чувствителен к регистру
символов, это касается как имен тегов, так и значений атрибутов. То есть <Table>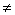 <table><tAble><TABLE>. <table><tAble><TABLE>.
Также существенным отличием языка XML от HTML является тот факт, что каждое
значение атрибута должно быть заключено в кавычки. Каждый элемент должен иметь
закрывающий тег (пример: <hr> - в HTML такое написание допустимо, в XML
элемент линии должен иметь закрывающий тэг: <hr/>).
Имена и символы
Символы в языке XML представляют собой числа, определенные в наборе символов
16-bit+ Unicode 2.1. Данный способ кодирования соответствует стандарту ISO/IEC
10646, описанному на сайте по адресу: //www.iso.ch.
Имена
В языке XML все имена должны начинаться с буквы, символа нижнего подчеркивания
( _ ) или двоеточия (:) и продолжаться только допустимыми для имен символами.
К числу последних относятся все вышеперечисленные символы, а также цифры, знак
дефиса (-) или точки ( . ). Имена не могут начинаться со строк “xml”,
“XML”, “xML”, “xmL”, “XMl”, “Xml”, “XmL”.
Пример. Это правильные имена: Book, BOOK, myname: Catalog, Книга.
Это не правильные имена: -BOOK, 101Далматинец, XMLForever, Лена+Петя=Любовь.
Структура документа
Правильно оформленный документ XML состоит из трех главных частей:
- Необязательный пролог
- Тело документа, состоящее из одного или более элементов, имеющее
форму иерархического дерева, которое может содержать символьные данные.
- Необязательный эпилог с дополнительной информацией, состоящей из
комментариев, команд обработки, а также пустого пространства, следующего за
деревом элементов.
Рассмотрим стандартный пример простого документа XML.
|
Документ
|
Пролог
|
<?xml
version="1.0" encoding="Windows-1251"?>
<!DOCTYPE
books SYSTEM "//yourserver.com/books.dtd">
<!-- Здесь можно размещать
комментарии и команды обработки
-->
|
Тело
|
<books>
<book category="BestSeller">
<Title>Книга
для тебя</Title>
<Author>Иванов</Author>
<Price>99.99</Price>
</book>
</books>
|
Эпилог
|
<!-- Здесь разрешается размещать комментарии и команды
обработки -->
|
|
|
Рассмотрим подробнее структуру приведенную выше.
Пролог
Каждый документ XML начинается со следующего элемента: <?xml version=“1.0”
encoding=”Windows-1251”?>. Здесь мы объявляем, что документ является документов
XML с кодировкой Windows-1251. Впрочем, кодировка может быть любая в зависимости
от кодировки текста.
Итак, пролог состоит из следующих атрибутов:
- version – обязательный атрибут, значение которого должно
быть равно 1.0 для поддержки следующих версий;
- encoding – необязательный атрибут, указывающий на кодировку документа
XML. Если атрибут не указан, то по умолчанию предполагается кодировка UTF-8
или UTF-16, в зависимости от формата начальной строки “<?xml”.
- standalone – необязательный атрибут, принимающий значения “yes” в
случае, если в документе содержаться все требуемые декларации типа документа
(Document Type Declaration), или “no”, - если декларации находятся в отдельном
файле. Забегая вперед, скажу, что декларации типа документа могут находится
как в самом документе XML, так и в отдельном файле одновременно, дополняя
друг друга.
Декларация типа документа
Декларацию типа документа не следует путать с определением типа документа.
Можно сказать, что декларация типа документа содержит внутреннее подмножество
и/или ссылается на внешнее подмножество определения типа документа.
Все допустимые (valid) документы должны содержать такого рода декларации, либо
ссылки на их внешний эквивалент (пример такой ссылки приведен ниже).
<!DOCTYPE books SYSTEM "//yourserver.com/books.dtd">.
Данный элемент «говорит», что представленная структура документа XML определяется
внешней декларацией books.dtd, находящейся по адресу //yourserver.com/
.
Тело
Тело состоит из элементов. Элементы – это основные строительные блоки разметки
XML. Элементы могут содержать подэлементы, символьные данные, ссылки на символы,
ссылки на объекты, команды PI (команды обработки), комментарии, разделы CDATA.
Все данные XML, кроме комментариев, команд обработки и пустого пространства,
должны содержаться внутри элементов.
Элементы отделяются друг от друга с помощью тэгов, состоящих из имени типа
элемента, заключенного в пару угловых скобок. Каждый элемент имеет открывающий
и закрывающий тэг, либо, если это пустой элемент (например, <pusto/>),
некий гибрид открывающего и закрывающего тэга, как показано в примере.
Все элементы должны быть вложены друг в друга. Это выглядит примерно так:
|
<a> <!-- открывающий
тэг “a” -->
<b> <!-- открывающий
тэг “b” -->
………………………………… <!-- некоторые
данные -->
</b> <!-- закрывающий
тэг “b” -->
<b> <!-- открывающий
тэг “b” -->
………………………………… <!-- некоторые
данные -->
</b> <!-- закрывающий
тэг “b” -->
</a> <!--
закрывающий тэг “a” -->
|
Таким образом, мы получаем некую иерархическую древовидную структуру с единственным
корневым узлом, называемым корнем документа. Корень в документе может быть только
один. Такой принцип составления документа можно сравнить с системным реестром
Windows, т.е. со структурой типа иерархическая база данных.
Для сравнения приведем два примера, как нельзя составлять документы XML.
|
<a>
<b>
…………………………………….
</a>
</b>
|
<a>
……………………………………………
</a>
<b>
…………………………………………....
</b>
|
Здесь все очевидно. В первом примере мы видим отсутствие вложенности тэгов,
а во втором – в документе существуют два корня.
Атрибуты
Часто необходимо связать некоторую информацию с элементом, а не просто включить
его в содержание последнего. Для этого существуют атрибуты. Атрибут представляет
собой пару имя-значение, записанное в одном из двух форматов:
attribute_name=”attribute_value”
attribute_name=’attribute_value’
Атрибуты подчиняются тем же правилам, что и строковые константы, т.е. значения
атрибутов должны быть заключены в двойные или одинарные кавычки, они могут содержать
ссылки на объекты, ссылки на символы и/или текстовую информацию.
Пример: <book category=”Fantasy”>. В данном случае мы имеем элемент “Book”
с атрибутом “category”, значением которого является слово “Fantasy”.
Специальные атрибуты
В рекомендациях комитета W3C по XML 1.0 определены следующие специальные атрибуты:
xml:space и xml:lang.
Атрибут xml:space служит для указания приложению сохранять пустые пространства.
Данный атрибут можно сравнить с тэгом <pre> в HTML, используемым для сохранения
форматирования документа.
Атрибут xml:lang введен для указания приложению о существовании текста
со специфической кодировкой, где надо учитывать порядок сортировки символов,
способы разделения слов при полнотекстовом индексировании и т.д. Указывая данный
атрибут, мы даем понять приложению, какой язык использует элемент с данным атрибутом.
Значением атрибута xml:lang является специльный двухбуквенный код, обозначающий
соответствующий язык: fr для французского, ja для японского. Также двухбуквенный
код может сопровождаться подкодами: en-US – американский английский, az-cyrillic
– азербайджанская кириллица.
Эпилог
В этой части документа XML могут использоваться комментарии и команды обработки
и/или пустое пространство. Однако при этом не ясно, должны ли команды обработки
применяться к предшествующим элементам или к последующим, если таковые имеются.
В этом и заключается основная проблема эпилога.
Большинство анализаторов XML (если не все) конец документа определяют по завершающему
тэгу. Соответственно, вся та часть, что находится после завершающего тэга, анализатором
будет игнорирована.
По мнению Тима Брея (один из авторов рекомендации XML 1.0) эпилог является
ошибкой проектирования и его не стоит использовать без необходимости. Также
следует иметь в Вилу, что скорее всего эпилог не будет обрабатываться другими
приложениями XML.
Ссылки по теме:
|
|
::::: мио пишет 06.03.2002 @ 18:50 | |
мда ... люди ... дошли ... наконец таки ...
XML forever ... и что?
Всё равно оформляя таким способом документы, мы понимает, что всё равно пока они не пригодны для отображения. А качать и устанавливать плагины всевозможные не хочется.
О чём я ?
Люди, пока не появится нормального средства отображения XML или хотя бы не будет нормального парсера, XML будет непригоден для документов.
Зачем можно использовать XML:
-- база
-- структура сайта
-- статистика
-- и всё что угодно, но не сами документы.
Когда XML стал появляться в массах (ну появляться в массах он стал намного раньше), в том смысле, что по XML стали появляться описания, книжки всякие, он привлёк сразу одним -- структура, удобная для восприятия.
Тогда и пришла в голову мысль, преобразовывать данные к XML структуре.
Возникли сразу несколько проблем:
-- обработать такую структуру
-- так, как она предполагает наличие объектов с одинаковыми именами, использовать дерево из ключей.
-- уметь преобразовавать данные из древовидной структуры в хеш хешей и обратно.
-- если с первой задачей мы справляемся почти сразу, то со второй надо будет пом.. помучаться.
Что имеем? Модуль на Си, позволяющий на лету обрабатывать XML, преобразовывать его в хешь, и дальше -- что хотим, то и делаем.
С данными проблемы не должно быть.
Итак. База пользователей:
<tree>
<userdata>
<user>
<name>mio</name>
<password>mJ32wA67</password>
<level>us:admin</level>
<key>681833614</key>
</user>
</userdata>
</tree>
Теперь можно задуматься.
Если у нас есть просто данные, которыми мы манипулируем (аунтефикация пользователей к примеру), то всё нормально, если не ... СКОРОСТЬ парсинга.
В чём проблема? Каждый раз, когда пользователь будет логиниться, программный комплекс должен будет обращаться к базе, парсить её, а дальше уже манипулировать данными, как ему заблагорассудится.
А зачем постоянно грузить всю базу, если можно её в виде хешей хранить в памяти. Будем считать, что кроме этой задачи нам больше не надо ни о чём беспокоиться, т.е. ограничения на использования памяти у нас нет.
Тогда всё упрощается.
Для манипулирования базой данных, мы можем использовать сервер, который просто все данные хранит в памяти, и при их изменении генерирует нужные XML. Т.е. раз в день делать push и генерить нужный нам XML в любом количестве, вплоть до разбивкой на страницы.
Т.е. хранить данные можно где угодно, когда угодно. И подгружать их по мере необходимости.
Итак. Теперь у Нас есть сервер.
Играем дальше.
Для чего вы делаете свой сайт? Вы часто его обновляете? И последний вопрос - зачем вы генерите всё время одно и тоже, если оно не изменилось ? Быстро ? Думаете ? Кому ? Вам или серверу? А если возьмём 10,000 обращений к серверу за секунду? не вылетел ? - повезло)
Итак. Зачем мы используем динамику ? -- потому что так проще. Зачем утруждать себя, чтобы генерировать HTML`ки, если можно просто его генерить. Ну да. Так намного проще.
Задача: описать структуру сайта, описать дейсвия (сценарии обработки действий), и, при изменении данных -- сгенерировать новую структуру.
Опять же возможен серверный вариант.
Мы описываем действия гостевой, объясняем, что такое добавление сообщения, объясняем, как обрабатывать данные, как разбивать на страницы, описываем шаблоны и всё. Забудьте пхп и перл) Забудьте всё.
Матрицы нет, есть только ложка.
Зайдите в администрирование и нажмите инстал. Радуйтесь.
Оно работает. Вы свободны.
все события и имены вымышлены, они даже не могли существовать в реальности.
А если серьёзно, если какие нибудь у кого то мысли будут, пишите на мыло, отвечу) если смогу)
|
 |
|
::::: мио пишет 06.03.2002 @ 19:30 | |
Рад, что на мою статью появилось так много комментариев. Я тут прочитал, что сейчас нет достойных средств для отображения XML документов. Я бы так не сказал: существует множество различных парсеров и т.д. Притом у нас есть такая вещь, как XSLT (об этом будет рассказано в следующих статьях). Единственная проблема заключается в межплатформенности. Парсер MSXML 4.0 очень хорош, однако при его использовани вы можете забыть о не Windows-системах, что противоречит основному принципу web-мастеринга - документы должны правильно отображаться на всех платформах.
Вот так. Еще раз благодарю за отзывы. А насчет того, что XML - это фигня, хотелось бы сказать, что одна из самых мощных систем электронной коммерции Micorsoft BizTalk строится как раз на XML.
|
|
::::: advocat пишет 07.03.2002 @ 20:42 | |
Вот что я скажу по этому поводу ... все равно как не крути, но я лично как предпочитал php, так и останусь висеть на нем ... так, что PHP FOREVER, и никакой хмл ему не конкурент ... тем более глупый язык, даже хтмл лучше ...
|
|
::::: Dolce пишет 08.03.2002 @ 00:19 | |
Ну, PHP имеено и надо с XML как-то юзать. Прикинь, у тя есть классная прогга, с config.inc.php файлом на 300 опций, ну просто ВСЁ мона настроить... мона либо в нём копаться и пытаться всё мастерить, либо через XML пропарсить и красиво через интерфейс позволить свою проггу настроить... гг... мелочь конечно, но приятно.
Начнём с того, что XML существовал за долго до HTML... вообще - HTML = кастрированный XML :)
|
|
::::: мио пишет 09.03.2002 @ 15:32 | |
мда ... люди ... вы о чём говорите ?
вы поймите, что XML -- это не язык программирования как таковой, это либо язык разметки, либо язык, но который ВЫ сами можете расширить, но сам по себе он просто пустой)
Я предложил использовать XML лишь как структуру, которую сам расширил, я написал для себя язык, который состоит из языка скриптования, таблиц и данных в XML, ну и парсера для HTML`а.
А ваш PHP, как был, так и останется обычным языком для простых скриптов.
Я предложил использовать его только лишь как структуру, для расширения того же php или perl.
Т.е. вам надо один раз написать правила, и пользоваться.
Я предложил язык, который описывает не ЧТО ДЕЛАТЬ, а КАК ДЕЛАТЬ. Тогда язык не играет значения, тогда важней сам алгоритм. Попробуй логически описать, как добавить в гостевую собщение, и как разбить на страницы. Получилось? Тогда Welcome Are You.
Всегда с вами ... мио)))
Ведьмочка Фаа -- Таинственное манит ? -- http://sunfaa.rosclub.ru/
|
|
::::: Neo пишет 09.03.2002 @ 23:27 | |
Да все вы тормоза!!! html+php = cool!!!
|
|
::::: мио пишет 11.03.2002 @ 16:05 | |
нео, зато ты крут)
наверное ас в серверных технологиях)
ты просто наверное совершенство)
|
|
::::: denz пишет 13.03.2002 @ 12:02 | |
xml, vml, ... все очень просто вот только врубиться надо в определенный момент... а не кричать тут "php cool!" РНР конечно кул... но не совершенство... но как модуль обработки баз данных цены нет!
|
|
::::: Саша пишет 13.03.2002 @ 15:12 | |
На сколько я так посмотрю для тех хто немного знает HTML для тех не составит труда освоить и XML
|
|
::::: teo пишет 14.03.2002 @ 11:01 | |
PHP,ASP,Perl - их много, и все позволяют обрабатывать XML, так что PHP здесь не при чем. Это из другой оперы совсем.
Я например использую ASP IIS5 для обработки XML. В будущем перепишу небольшие модули ASP на Java и оставлю без изменений XSL шаблоны. И все будет работать.
Основная логика работы в XSLT лежит. И не недо заморачиваться способом реализации.
p.s.
XSLT вот это круто
Жду реализации 2 версии у MS
Основан на XML кстати, что позволяет себя обрабатывать
|
|
::::: makut пишет 25.03.2002 @ 17:41 | |
Все круто. Но дайте же пощупать, как с этим работать. От абстракции уже зубы болят. Конкретных бы примеров.
|
|
::::: Shurick пишет 06.04.2002 @ 15:39 | |
Чё вы тут!!?? Сool, не Сool, да вы чё, вот это и правда Сool. Правильно makut пишет! Да и вообще: кастрированный.....? Нет блин, вот XSLT - это Cool. Вас не задрало говорить, что Cool, а что не Cool! Я не спец в XML, но СУЩЕСТВЕННОЙ разницы между HTML не увидил. Кстати, XML грузится ДОЛЬШЕ HTML!!!!
|
|
::::: Shurick пишет 06.04.2002 @ 15:40 | |
|
Опять же благодарю всех за свои отзывы. Есть конструктивные (особенно те, что написал МИО), а есть и не очень - вроде: "PHP Cool", - или: "XSLT Cool". Не важно, что круче. Я, например, написав эту статью (кстати, на следующей неделе будет продолжение. Статья будет посвящена DTD и схемах XML), принялся за создание приложений с использованием компонентов Delphi 6 WebSnap. Язык XML - это очень большой шаг к стандартизации. У нас так много различных систем и технологий. Каждый web-мастер всегда стоит перед проблемой различного отображения своих сайтов в разных браузерах. Разработчика интернент приложений беспокоят проблемы переносимости его приложений на другие платформы. XML - не панацея от всего этого, но данный язык дает разработчику множество преемуществ. Главное из инх - это то, что XML поддерживается везде. А теперь с появлением платформы .NET для XML наступили просто чудесные времена. Так что не надо спорить, что лучше - чат на PHP или структура на XML. Каждый волен выбирать себе свою технологию (или несколько технологий) и работать с ней (с ними).
|
|
|
::::: Mik пишет 07.03.2004 @ 18:31 | |
А как сделать так , чтобы данные в из xml-документа отображались в браузере (не текст xml-документа, а именно данные)?
|
Я в статье так и не прочитал того самого главного, зачем взялся ее читать - зачем нужен XML? Если для хранения данных - чем хуже любые другие форматы? Если для отображения данных, чем хуже HTML?
|
|
::::: LoKi пишет 25.06.2004 @ 17:39 | |
Он лучше тем что он и нужен и для хранения и для отображения данных. Именно это отличает его от других форматов.
|
|
::::: serg пишет 18.07.2007 @ 14:30 | |
уважаемые, как только хостер начнёт возмущаться (кровопийца!) по поводу загруза его любимомго сервера, на котором ещё ХЗ скока сайтов - так и начнёте думать, а стоит ли использовать ХМЛ (и платить хз скока у.е. за выделенный сервак), или может выбрать другой путь, менее грузящий ресурсы.
|
| |